Pure AI.
Shipped in days.
MLGround is an AI-native product studio. You tell us what to build. We deliver a working AI product - backed by real infra, real users, real audit trails - in days, not quarters.

Median brief → flag, last 7 builds
Production AI systems shipped, 2 more in flight
Real user actions per day on systems we operate
Recurring cloud spend on our largest agent
An AI-native dev shop, not a consultancy.
Engineers, not deck-makers
Every person at MLGround writes code daily. We don't sell roadmaps. We sell shipped software - production AI features that survive contact with real users, real money and real audit logs.
See what we've shippedAI-first, by default
Generative AI is the default tool, not a feature flag. Chat agents, autonomous workflows, document understanding, retrieval, evals - we build them as primitives, not bolt-ons.
Tell us what to buildPast the API key.
Anyone can paste an OpenAI key. We deploy your own models, build the data that trains them, and run the agentic stack that keeps them honest.
Worth training on.
Scrape, label, synth, distill. PII scrubbed, dedup-ed. Eval set first.
LoRA, QLoRA, DPO, GRPO.
Fine-tune Llama, Qwen, Mistral via Axolotl & Unsloth. Distill frontier teachers into 7B-70B students you can afford to run.
vLLM, TRT-LLM, SGLang.
FP8, speculative decoding, multi-LoRA, KV-cache reuse. H100, L40S or on-prem. Air-gapped on request.
Agents that don't loop.
Planner + executor. Strict-schema tools. Cost, latency, step guardrails. Traces in Langfuse / OTEL.
AI is the default. Not a sprinkle.
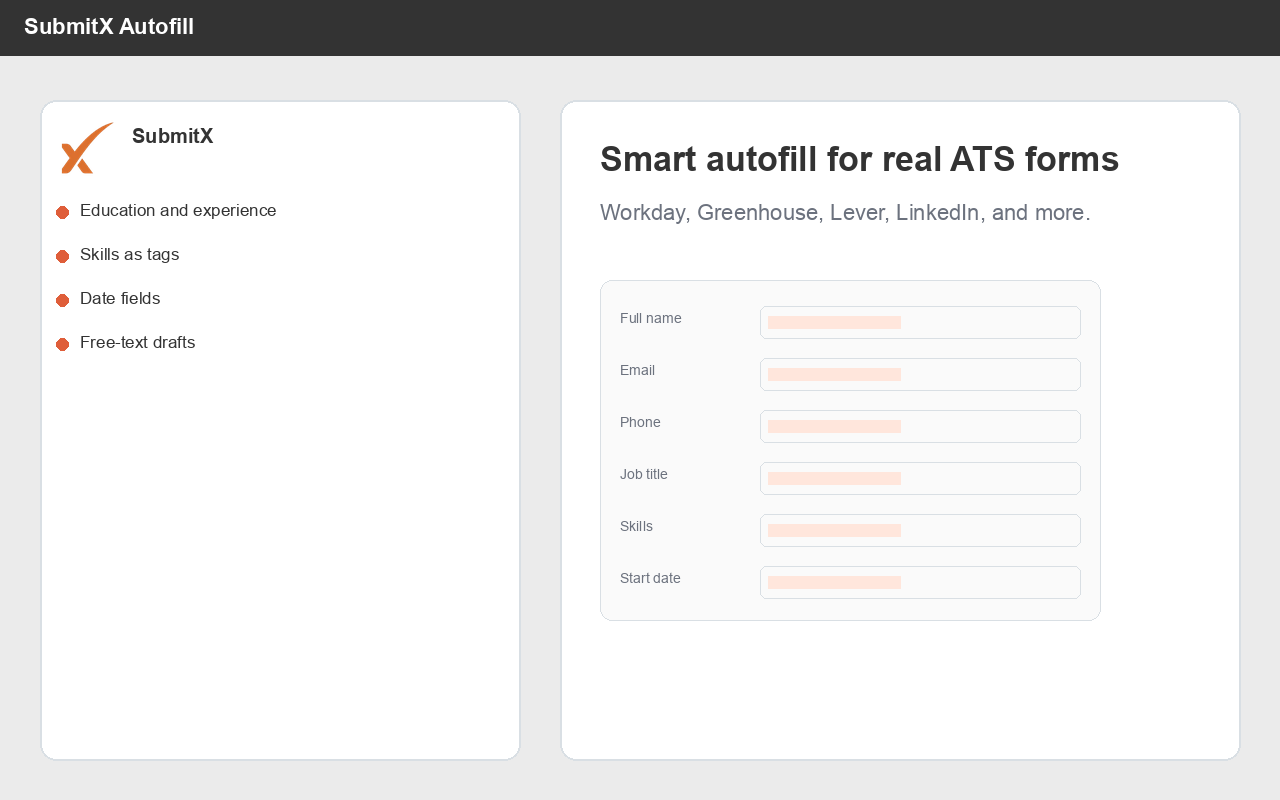
Agentic AI products
Chrome extensions, browser agents, autonomous workflows. We've built one that submits 30,000+ job applications every day across 47 ATSes - yours could automate something just as gnarly.
See SubmitX →
Self-hosted LLMs in your VPC
Your own model, in your own network. We fine-tune Llama, Qwen, Mistral with LoRA/QLoRA and DPO, then deploy on vLLM, TensorRT-LLM or SGLang with FP8 quantization and speculative decoding. Latency you control. Cost you predict. Data that never leaves your perimeter.
Talk to us →
LLM features inside your product
Chat, copilots, structured extraction, smart search, voice. We wire them into your existing stack - Next.js, Rails, Django, Flutter - without a six-month rewrite.
Talk to us →
Evals, RAG, AI infra
Vector stores, retrieval pipelines, evaluation harnesses, prompt-as-code. Boring, fast, cheap - Lambda + DynamoDB + S3 only spending money when a user actually uses it.
Talk to us →What we ship, concretely.
SubmitX is one of many. A non-exhaustive list of the shapes we've shipped — each in 2-4 weeks, each live in production.
 Document understanding
Document understanding
Extraction agents.
Vision LLM pulls structured JSON from invoices, contracts and claim forms — 12-page PDFs in ~4s, scanned or rotated. Human review under confidence.
Built on: Claude 4.7 vision, GPT-4.7 vision, Qwen2.5-VL, PaddleOCR, Pydantic schemas, AWS Textract
 Voice
Voice
Real-time voice agents.
Speech-in, speech-out, tool-calling in under 600ms. Tuned for interruptions, accents, background noise. Plug into Twilio, LiveKit, or your SIP trunk.
Built on: OpenAI Realtime, Cartesia, Deepgram, ElevenLabs, Pipecat, LiveKit Agents
 Customer support
Customer support
Support copilots wired to your ticket queue.
RAG over your tickets, docs and runbooks. Agent drafts, your team approves. ~$0.003 per draft. Ships in 5 days against Zendesk, Intercom, Front.
Built on: pgvector, Cohere Rerank-3, Voyage embeddings, Zendesk & Intercom APIs
“But AI can do this
for $200, right?”
Yes. Sometimes. Here's the part it can't do.
A repo with a clear bug? Cursor fixes it for $4. A well-scoped feature with a written spec? Devin ships it for under $1k. Here's what you can't hand to an AI:
- “Should we fine-tune Llama or stay on OpenAI?” - a call, not a task.
- “Our agent loops 5% of the time and we can't reproduce it.” - debugging emergent systems.
- “Build the eval set.” - there isn't one yet.
- “We have 4 years of support tickets. What's worth training on?” - judgment over data.
- “Sign the MSA. Be the named vendor for procurement.” - accountability.
- “Take the page when prod breaks at 3am.” - ownership.
We use Cursor and Claude Code every day. That's why a small team ships like a big one. The $18k isn't the code. The code is cheap. The $18k is the call on what code to write, the eval that proves it works, and the human who answers when it doesn't.
Bring us the hard ones. Cursor can have the easy ones.
Three ways to start.
All in USD. All cancellable.
$4,900
5 days · one engineer
You ship us a repo, a Loom and your worst prompt. We ship back a written technical diagnosis, a working prototype on a branch, and a fixed-price quote for what's next.
Best if you're not sure what's broken yet.
$18,000
2 weeks · two engineers
A scoped feature, designed Monday, behind a flag by Friday-two. Daily Slack, written end-of-day notes, Zoom only when faster than typing.
Best if you know what to build and want it live this month.
$24,000+ / mo
2-3 engineers · monthly rolling
We sit inside your Slack and your repo. We ship the way your team ships. Cancel after any month, no penalty.
Best if you have a 3-6 month roadmap and no one to drive it.
All four US timezones covered · NDAs & MSAs signed in 24 hours · Wise, Stripe or US bank wire · W-8BEN-E on request
Skin in the game.
We write the sprint goal Monday, in plain English, in your repo's README. If we don't ship it by Friday-two:
- You get the unfinished portion refunded.
- We work the next sprint free — until it ships.
No retainer ratchets. No “scope crept.” No “we'll true-up at the end.” If we miss, we eat it.
Applies to work where we set the scope. We can't guarantee what we can't measure.
Day 1: brief.
Day 3: prototype.
Day 14: live.
No discovery month. No three-phase Gantt. The first thing we ship is the thing you wanted - narrower than you imagined, better than you expected. We iterate against real users from week one.
Case study: SubmitX, 14 days end-to-end →
Unlocking the possibilities of human creativity and machine processing.
Generative AI isn't a feature. It's the new substrate. We help founders, ops teams and product leaders cut through the hype and ship the smallest useful thing - fast - so you can learn under real load instead of in a Notion doc.
Tell us what to build
"SubmitX submits 30,000+ real job applications every day across Workday, Greenhouse, Lever, Ashby and 47 other ATSes. MLGround built the agent, the dashboard, the payments and the Telegram bot - in 14 days."
Featured product · Built with MLGround
14 days
Idea to live in production.
47
ATS adapters covered.
$0
Committed cloud spend at launch.
Read the case study →
"You don't need to send your data to OpenAI to ship AI. We fine-tune Llama, Qwen and Mistral, then deploy them on vLLM with FP8 quantization and speculative decoding - in your VPC, on your GPUs, behind your firewall."
Capability · In-house LLM deployment
0 bytes
Customer data leaving your perimeter.
3-8×
Typical inference cost reduction vs. frontier APIs.
<1s
P95 latency on a single H100, 8B fine-tune.
Talk to us →
"We don't bill hours. We bill outcomes. A two-week sprint with MLGround replaces a six-month engagement at a traditional consultancy - at roughly a fifth of the cost."
- Nikhil Bharadwaj Reddy Sagili, Founder & CEO
0 layers
No PMs, no AMs, no recruiters. The engineer who quotes you writes the code.
2 weeks
Average sprint to production.
100%
Founder involvement on every project.
Start a project →Got a problem worth shipping fast?
30 minutes is usually enough for us to know whether we can build it, how long it'll take, and what it'll cost.
Book a call